Google Document AI, IDP Platform on Vertex AI
On This Page
- Overview
- What users say
- Google Document AI video
- How Document AI handles extraction
- Use cases
- Healthcare revenue cycle and clinical workflows
- Enterprise document processing
- Cloud infrastructure for specialized applications
- Technical specifications
- Pricing
- Competitive positioning
- Resources
- Company information
Google Document AI is an API-first intelligent document processing (IDP) service built on Vertex AI, using Gemini 3 language models for extraction, classification, and layout parsing. It targets developers and enterprises already standardized on Google Cloud, offering usage-based pricing and deep integration with the broader Vertex AI infrastructure.
Overview
Google Document AI is not a standalone IDP platform in the traditional sense. It is an extraction and document understanding service that organizations connect to their own workflow orchestration, human-in-the-loop review, and case management tooling. This developer-first architecture suits enterprises building custom pipelines on Google Cloud but creates friction for teams seeking a unified, out-of-the-box IDP solution.
The platform has accelerated its model cadence significantly in early 2026. Between January and April 2026, Google released Gemini 3 Flash and Pro-powered custom extractors in preview, launched custom splitter v1.5 at general availability (GA), and introduced fine-tuning upgrade paths from v1.4 to v1.5 models. Template-based processors achieve over 95% precision and recall on structured documents such as invoices, with confidence scores available for field-level validation in production.
Healthcare is the clearest proof point for Document AI at scale. At HIMSS 26 in March 2026, Google Cloud announced deployments with CVS Health, Highmark Health, Waystar, Quest Diagnostics, and Humana, covering revenue cycle management, lab result interpretation, and clinical workflow automation. These deployments use Document AI's extraction layer as the foundation for downstream agentic decision-making.
What users say
Practitioners consistently describe Document AI as accurate and well-integrated within Google Cloud, but note the platform requires significant additional engineering to reach production-grade IDP workflows. Teams report that the extraction quality on structured documents like invoices and forms is strong, while unstructured document handling has improved materially with Gemini-powered models. The absence of built-in workflow orchestration, human-in-the-loop review, and case management is the most common friction point cited by evaluators comparing Document AI against end-to-end IDP platforms.
Organizations already running workloads on Google Cloud find the IAM integration, VPC service controls, and regional data residency controls straightforward to configure. Teams coming from other cloud environments or seeking a vendor-managed IDP experience tend to find the setup overhead significant relative to alternatives that bundle orchestration with extraction.
Google Document AI video
This video demonstrates Google Document AI in action, covering the platform's extraction, classification, and layout parsing capabilities through Vertex AI.
 Click to load video from YouTube
Click to load video from YouTubeHow Document AI handles extraction
Google Document AI routes documents through specialized processor models depending on document type and processing requirement. As of early 2026, the platform offers three model tiers for custom extraction: Gemini 3 Flash (120 pages per minute quota), Gemini 3 Pro (30 pages per minute), and legacy v1.x models scheduled for deprecation on June 30, 2026.
Custom extractor models powered by Gemini 3 Flash and Pro entered preview on January 27, 2026, with ML processing available in US and EU regions. The Flash variant prioritizes throughput for high-volume workloads; the Pro variant trades speed for accuracy on complex or ambiguous documents. Both support document-level prompting, which launched January 12, 2026 and allows organizations to inject business context at the document level to improve field extraction accuracy without retraining.
Layout parsing received parallel upgrades. Gemini 3 Flash and Pro layout parser models entered preview on February 9 and January 27, 2026 respectively, improving table recognition and reading order on PDF files. A web interface for the layout parser entered preview February 16, 2026, adding document view display, JSON visualization, and image and table annotation directly in the console.
For document splitting and classification, custom splitter v1.5 reached GA on March 27, 2026, offering zero-shot splitting, classification, and confidence scores without requiring labeled training data. Custom classifier and splitter v1.6 entered preview on March 23, 2026, powered by Gemini 3 Flash and Pro, continuing the platform's shift away from template-based approaches toward zero-shot and few-shot extraction.
Fine-tuning is now iterative. The custom extractor fine-tuning upgrade capability launched March 31, 2026, allowing users to upgrade from v1.4 to v1.5 models while preserving prior configurations, reducing the cost of adopting newer model versions for teams with established training datasets.
Use cases
Healthcare revenue cycle and clinical workflows
Waystar's AltitudeAI, built on Google Cloud, has prevented more than $15 billion in denied claims and reduced appeal and documentation time by 90%. The system uses Document AI's extraction capabilities as the foundation for autonomous revenue cycle management decisions.
Highmark Health's Sidekick platform scaled from 1 million to 6 million prompts in just over one year, delivering an estimated $27.9 million in AI-enabled value for 2025. Allegheny Health Network, part of Highmark, uses a Sidekick-based workflow to automate the first draft of complex research protocols through an IRB protocol and consent builder. Richard Clarke, Chief Data and Analytics Officer at Highmark Health, stated in March 2026: "The next chapter is bringing multi-agent support to employees."
Quest Diagnostics launched Quest AI Companion, a HIPAA-compliant chat feature for lab result interpretation via the MyQuest app and portal. Humana deployed an Agent Assist solution using Gemini Enterprise for Customer Experience to support call center operations.
Enterprise document processing
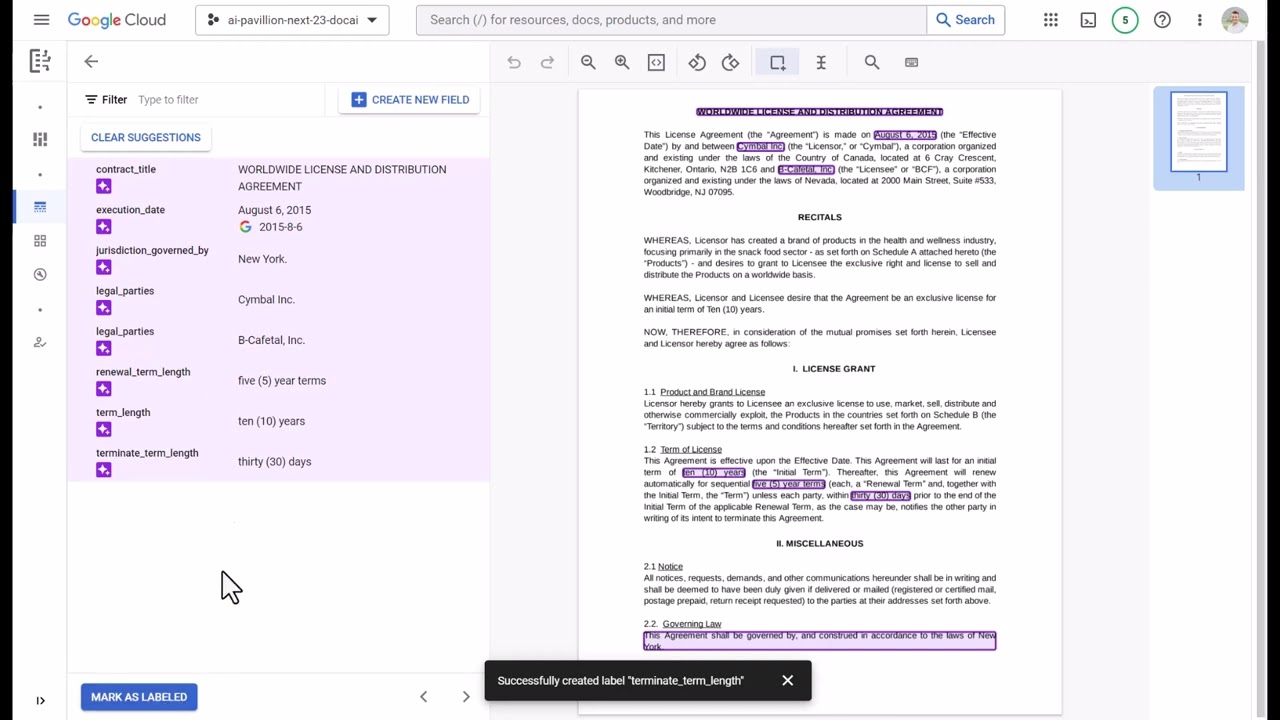
For a hands-on walkthrough of Document AI configuration, see the Google Document AI guide and form recognition guide. Developers building LLM-powered extraction pipelines on top of Google's models may also find LangExtract, Google's open-source Python library for structured information extraction with source grounding, a useful companion tool.
Cloud infrastructure for specialized applications
Google Cloud provides backend infrastructure for applications requiring real-time data processing at scale. Teams evaluating open-source IDP platforms built on Google Cloud infrastructure may also consider Unstract, a no-code LLM platform for production-grade document extraction with hallucination mitigation. Organizations requiring video intelligence alongside document AI on the same cloud infrastructure may find VIDIZMO's enterprise video and document AI platform relevant, particularly for government and evidence management use cases.
Technical specifications
| Component | Specification |
|---|---|
| Custom extractor models | Gemini 3 Flash (120 pages/min), Gemini 3 Pro (30 pages/min) |
| Layout parser | Gemini 3 Flash and Pro, PDF table recognition and reading order |
| Custom splitter | v1.5 GA (zero-shot), v1.6 preview (Gemini 3-powered) |
| Max file size (online) | 40 MB (increased from 20 MB, June 2025) |
| Max pages (online/sync) | 30 pages per request |
| Project limits | 30,000 documents or 250,000 pages per project |
| Import limits | 5,000 documents per import |
| Structured doc accuracy | 95%+ precision and recall on invoices and forms |
| Vector Search | 2.0 GA: hybrid search, auto-embeddings, PSC/PGA/VPC support |
| RAG Engine | Serverless mode public preview (April 3, 2026) |
| Regions (custom extractors) | US and EU (January 2026 onward) |
| Compliance | SOC 2, ISO 27001, HIPAA |
| Security | Encryption at rest and in transit, RBAC via IAM, SSO via Google Cloud Identity, IAM deny policies, VPC service controls with identity groups |
Pricing
Enterprise OCR
Pages 1 to 5,000,000/month
- $0.60 per 1,000 pages above 5M pages/month
- Enterprise Document OCR Processor v2.1.1
- Available in US, EU, and additional regions
Custom Extractors
Pages 1 to 1,000,000/month
- $20 per 1,000 pages above 1M pages/month
- Gemini 3 Flash and Pro models
- Fine-tuning and document-level prompting included
Specialized Parsers
Invoice, bank statement, and domain parsers
- Invoice parser: $0.10 per 10 pages
- Bank statement parser: $0.75 per classified document
- Processor hosting: $0.05/hour per deployed version
- Capacity reservation: $300 per extra page-per-minute/month
New Google Cloud customers receive $300 in credits valid for 90 days, applicable to Document AI usage.
The usage-based model creates cost predictability for low-to-medium volume workloads but becomes expensive at scale. Capacity reservation offers cost optimization for high-volume processing but requires upfront commitment. This contrasts with subscription-based competitors like UiPath and Automation Anywhere, which may offer better economics for organizations with unpredictable document volumes.
Competitive positioning
Google Document AI competes against UiPath, Automation Anywhere, Blue Prism, Laserfiche, and Kudra in the IDP vendor landscape. The core differentiator is also the core limitation: Google positions Document AI as an extraction and document understanding service, not an end-to-end workflow platform. Organizations must integrate additional tooling for human-in-the-loop review, case management, and downstream process automation.
This developer-first approach appeals to enterprises already standardized on Google Cloud infrastructure. It creates friction for organizations seeking unified platforms where extraction, review, and orchestration ship together. Unlike cloud-only competitors that bundle workflow management with extraction, Google's architecture assumes the buyer will assemble the pipeline.
The June 30, 2026 deprecation of legacy processors, including identity parsers, tax and finance parsers, mortgage and banking parsers, procurement processors, and summary processors, forces customers toward custom extractors and Gemini-based foundation models. The migration path is documented but operationally disruptive for teams with production workloads on legacy processors. Organizations with large fine-tuned custom extractor deployments face potential vendor lock-in as the platform consolidates around Gemini models.
Regional coverage remains narrower than competitors offering on-premises deployment. Gemini-powered custom extractors are available in US and EU regions as of January 2026. Enterprise Document OCR v2.1.1 added asia-southeast1, australia-southeast1, europe-west2, europe-west3, and northamerica-northeast1 in February 2025, but organizations requiring on-premises deployment for data residency compliance will need to evaluate alternatives.
Legacy processor deprecation: June 30, 2026. Identity parsers, tax/finance parsers, mortgage/banking parsers, procurement, splitting, and summary processors will be discontinued. Organizations running production workloads on these processors should begin migration to custom extractors or Gemini-based models before this date.
Resources
- Google Vertex AI, unified AI platform for model training, deployment, and pipeline orchestration
- Document AI release notes, official changelog covering model versions, capability launches, and deprecation timelines
- Document AI limits reference, current file size, page, and project limits
- Google Cloud Document AI, service overview, processor catalog, and quickstart guides
Company information
Google is headquartered in Mountain View, United States, and operates Google Cloud as its enterprise infrastructure and AI services division. Document AI sits within the Vertex AI platform alongside Vector Search, RAG Engine, and the Gemini model family. The company's investment in AI infrastructure includes secured agreements for small modular nuclear reactors to power next-generation AI data centers, joining Amazon, Meta, and Microsoft in securing dedicated clean energy for AI computing at scale.