Tiny IDP: IDP Software Vendor
On This Page
Page contributed by Albert Vazquez.
Purpose-built document parsing API from Invofox, a Y Combinator-backed company, extracting structured JSON from invoices, receipts, payslips, bank statements, and custom document types without prompt engineering. Listed in our IDP vendor directory.
 Click to load video from YouTube
Click to load video from YouTubeOverview
Tiny IDP is the commercial API product of Invofox, a Y Combinator-backed company that launched its document parsing service in January 2026. The platform uses purpose-built extraction models tuned for specific document types rather than routing every document through a general-purpose frontier model. This architectural choice is the product's central differentiator: Invofox argues that specialized models eliminate the prompt engineering and output parsing overhead required when using GPT-4o or Claude directly.
The Nanonets IDP Leaderboard published in March 2026, which tested 16+ models across 9,000+ real documents, provides independent support for this positioning. Nanonets OCR2+ scored 80.8 on the IDP Core benchmark at $10 per thousand pages, matching Claude Sonnet 4.6 at the same score and trailing GPT-5.4 (83.2) while costing less than half the price. The benchmark confirms that purpose-built extraction models can match frontier models on structured extraction tasks, validating the market segment Invofox occupies.
The platform processes invoices, receipts, payslips, bank statements, and configurable custom document types. It handles multi-document PDFs automatically, separating batched files into logical sub-documents before extraction. A built-in document type classifier routes each document to the correct extraction schema without requiring per-request configuration. European data center hosting with GDPR compliance and zero data retention addresses regulated industry requirements.
Comparable IDP vendors include Parashift and Rossum.
How Tiny IDP handles document extraction
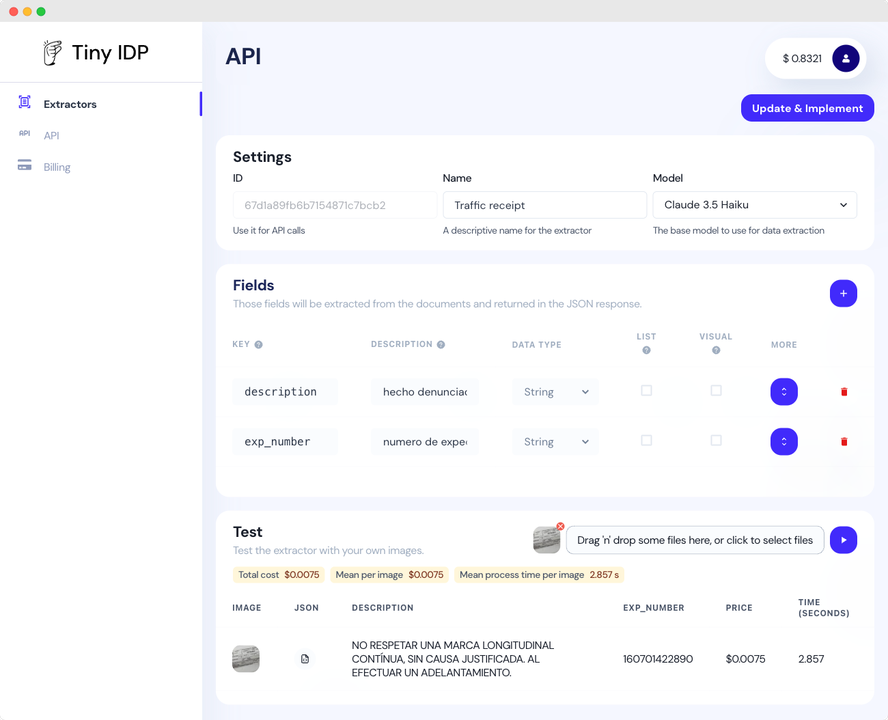
Invofox's API follows a three-step flow documented in its August 2025 technical comparison: POST /v1/ingest/uploads returns an importId, GET /v1/ingest/imports/{importId} returns documentId values, and GET /documents/{documentId} returns the parsed result. The response includes the original document image and extended metadata fields not present in raw GPT-4o or Claude outputs.
Beyond extraction, Invofox applies a proprietary validation layer that verifies and autocompletes extracted data fields. This reduces downstream validation work compared to raw LLM outputs, which require custom post-processing to catch missing or malformed values. Anmol Baranwal, an open-source developer who tested the API against GPT-4o and Claude Sonnet 3.5, reported: "It returned the fully parsed invoice JSON out-of-the-box. All fields were correctly extracted and validated. The output schema was exactly what we needed, with no extra coding."
The automatic document separation capability handles a production-relevant problem in accounts payable workflows: batched invoice PDFs containing multiple mixed documents. Invofox groups pages into logical sub-documents automatically, removing a preprocessing step that teams using raw LLM APIs must build themselves.
Use cases
Invoice and accounts payable processing
Invofox's core tuning targets commercial financial documents. The API extracts line items, tax calculations, vendor details, and payment terms from multi-language invoices without custom schema configuration. For accounts payable teams processing high-volume batched PDFs, the automatic document separation removes a manual splitting step before extraction begins.
Payslip and HR document processing
The pretrained classifier identifies payslips and routes them to a dedicated extraction schema covering gross pay, deductions, net pay, and employer details. HR and payroll teams processing employee documents benefit from structured output that maps directly to payroll system data models without transformation layers.
Bank statement reconciliation
Bank statement extraction captures transaction histories, opening and closing balances, and account metadata in structured JSON. Finance teams running reconciliation workflows can ingest the output directly into accounting systems without intermediate parsing steps.
Custom document types
Beyond the pretrained document types, Invofox supports configurable extraction schemas for custom document categories. Teams with proprietary document formats can define output structures that match their existing data models, reducing integration complexity.
Where accuracy limits apply
The Nanonets IDP Leaderboard benchmark data identifies two structural limitations relevant to any purpose-built extraction vendor, including Invofox. Sparse, unstructured table extraction scores below 55% for most tested models. Handwriting OCR has not exceeded 76% accuracy across any model in the benchmark, with Gemini 3.1 Pro holding the top score at that ceiling.
For Invofox customers whose document workflows include handwritten forms or complex unstructured tables, these are category-wide accuracy ceilings that specialized tuning may not overcome. The benchmark does not test Invofox directly, so the specific scores for Invofox's models on these tasks are not publicly available.
Technical specifications
Invofox abstracts model selection and optimization behind a clean API surface. Organizations interact with document types and output schemas rather than managing underlying model infrastructure.
| Feature | Specification |
|---|---|
| Deployment | European cloud API |
| Input formats | PDF, JPEG, PNG, TIFF |
| Output format | Custom JSON schemas |
| Response time | Under 5 seconds consistently |
| Data retention | None, GDPR compliant |
| Pricing model | Contact sales for pricing |
| Backing | Y Combinator |
Zero data retention aligns with EU regulatory requirements and provides assurance to enterprises handling confidential financial and HR records. The European data center addresses data residency requirements for organizations that cannot route documents through US-based infrastructure.
Pricing opacity: As of August 2025, Invofox does not publish pricing. Prospective users must contact the sales team for a commercial offer. This contrasts with GPT-4o and Claude, which publish per-token pricing directly, and creates evaluation friction for procurement teams running competitive cost modeling before a sales conversation.
Market context
The Graip.AI 2026 IDP trends analysis frames the current enterprise buying environment: 95% of generative AI pilots did not deliver expected value or stalled before scaling, according to MIT Sloan Management Review (2025). Enterprise budgets are concentrating on vendors demonstrating live workloads and measurable ROI rather than general-purpose demos. Karyna Mihalevich, Chief of Product at Graip.AI, stated: "Successful IDP starts long before automation. It requires a shared understanding of document quality, process maturity, and decision logic across the organization."
Invofox's Y Combinator backing and focus on production-ready JSON output without prompt engineering aligns with this shift toward demonstrated ROI. The absence of published customer outcome data or case studies in available sources is a gap in the evidence base for evaluators requiring proof of live workload performance.
Invofox competes not only against raw LLM APIs but against other specialized extraction models. The Nanonets leaderboard shows the specialized extraction segment is crowded: multiple purpose-built models now match frontier models on core tasks at lower cost. Differentiation increasingly depends on document type coverage, validation quality, and integration simplicity rather than raw extraction accuracy alone.
Resources
Company information
- Website: tiny-idp.com
- Email: info@tiny-idp.com
- Backing: Y Combinator